Never Staff to the Peak
You can't lay off someone you never hired
- Publish Date
- Authors
- Justin Searls
Missing in the coverage about the economic slowdown and ensuing tech layoffs is that this was all predictable years ago. It didn’t have to be this way. Many of these layoffs never had to happen, because a huge number of the roles being eliminated never made sense as long-term, full-time positions to begin with.
From 2014 to 2021, the number one reason companies gave for not engaging Test Double was, “we’re looking for full-time employees, not contractors.” Now, many of those same companies are making the painful decision to cause much more pain for those full-timers by laying them off.
Our advice at the time was and continues to be this: if you staff full-timers to meet the peak of your company’s demand for engineering capacity, be prepared for when that demand dips. Because it always dips.
(Almost nobody ever takes this advice, because I’m a consultant who sells consulting services on contract, so of course I’d be saying that.)
But having observed, worked with, and advised a number of engineering leaders at all kinds of businesses, it feels like the following chart should be common knowledge by now:
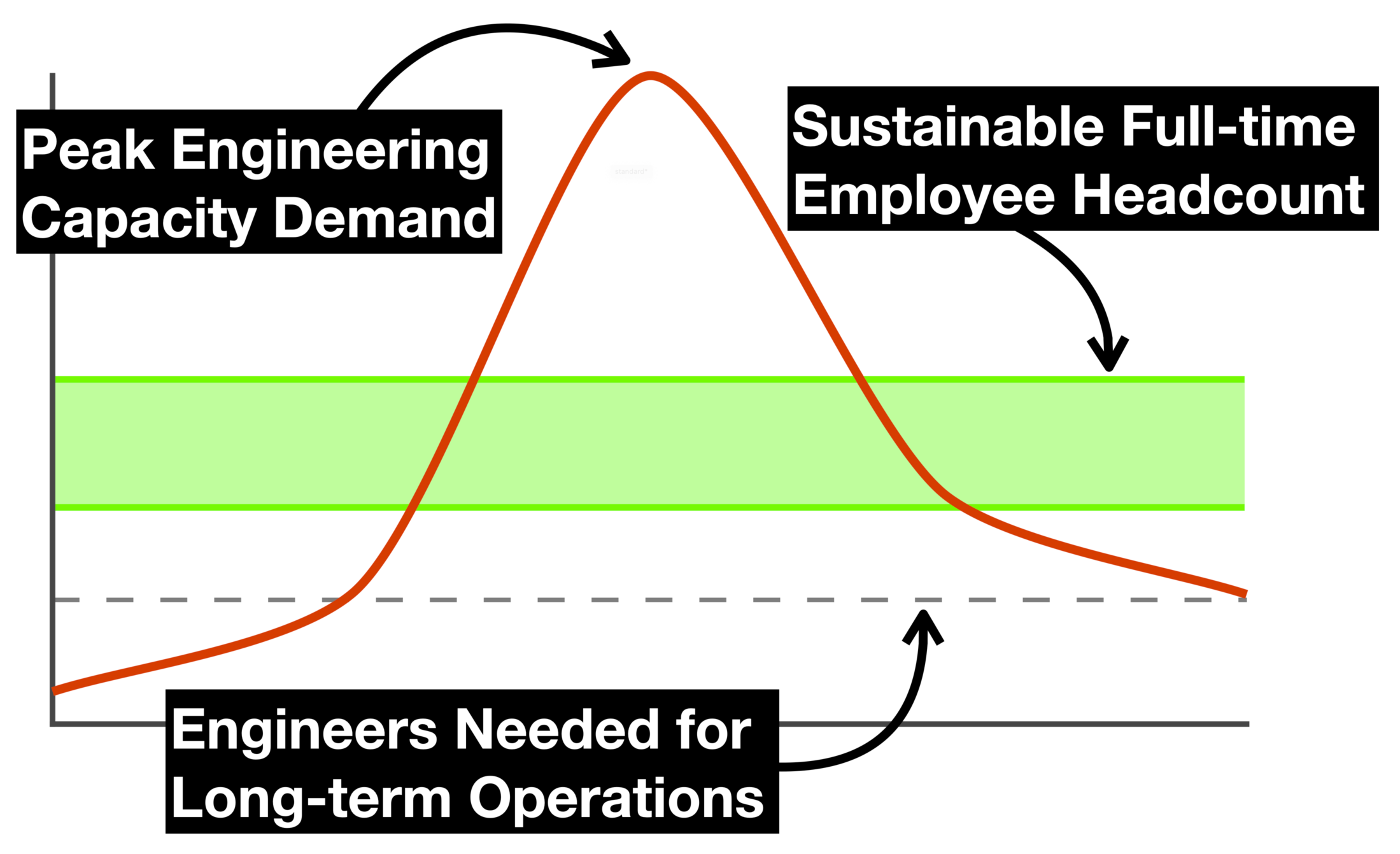
Put plainly, a perfectly sensible way to go about staffing an engineering organization would be to:
-
Hire as many full-timers as needed for long-term operational maintenance, plus some amount of additional capacity to both pursue new opportunities for innovation and to ensure there’s sufficient slack in the system to prevent short-staffed, short-sighted decision-making
-
Contract temporary help for ambitious undertakings in order to meet their commensurate increase in demand for engineering capacity. Ideally, pick an agency that collaborates as a strategic partner, whose engineers integrate seamlessly into your org without having to be managed by it, and who can elevate your teams by conferring outside skills and experience (yes, I’m describing what Test Double strives to be)
Why layoffs are occurring now is better covered elsewhere. How we got into this situation also warrants further investigation, but I’ll leave that to others.
For this discussion, let’s focus squarely on the consequences of the ideological imperative that leads countless tech firms to recruit full-time employees right up to the point their demand for engineering capacity peaks. VCs actively advised portfolio companies to do this because their investment return was proportional to any growth that would goose valuation in the eyes of later investors—the bigger the offices, the more highly sought-after the employees, the more snack stations, the better. The subsequent decade of unprecedented, uninterrupted growth only confirmed this bias and it has now taken deep root in the minds of a generation of engineering leaders. I now frequently encounter VPs of Engineering and CTOs who have never engaged an outside firm for help of any kind—even after failing to find new hires and experiencing costly delays of urgent and important work.
The pain of having to terminate the employment of their friends and colleagues may trigger some healthy reflection by those leaders. With any luck, it’ll even challenge the belief that every commit needs to be traceable back to a W-2 statement generated by their payroll system.
But the risk of future layoffs was never even my primary motivation for warning against exclusively relying on full-time hires! The bigger problem is the predictable pattern of technical and organizational dysfunction that gradually emerges after the launch of whatever Big Thing everyone is working on.
The Devil finds work for idle hands
Contrary to the vibe of this moment, when businesses have more engineers than valuable work for them to do, they actually tend not to lay people off as a first resort. Instead, management redirects extra capacity to lower-priority areas. Sometimes this is incredibly useful, because businesses also tend to fail to prioritize “second-order” concerns like technical debt, performance optimization, security, accessibility, and testing. But just as often, low-priority work breeds low-value complexity which leads to low-functioning engineering organizations.
Because most organizations are bad at saying “no” to bad ideas, having a surplus of engineering capacity is a dangerous thing.
Tackling rainy day list items may feel productive and valuable, but there are reasons why great software always seems to focus on doing a few things well, whereas horrible software often touts many more bullet point features. Reaching too deep down the feature backlog means more complicated user interfaces, harder-to-change codebases, and slower builds. And once the product does everything anyone ever imagined it could, the pain of working in the resulting swamp of complexity inevitably leads to architectural adventurism. Break up the monolith! Replatform onto a more modern tech stack! Rewrite the app, but simpler this time! By this point, nobody even remembers the moment of peak demand, much less considered that the product would be in better shape if they’d ramped down and let finished things be finished.
Regardless of whether additional complexity is essential (valuable) or incidental (waste), all complexity adds to the carrying cost of software. As a result, doing low-priority work costs the business twice: paying people to build things it doesn’t need, sure, but also paying higher maintenance costs on the existing things it really did need. That’s because, as is often forgotten: as complexity goes up, maintenance costs increase in super-linear proportion!
Somewhere, an engineer is painstakingly fixing broken tests that are an order of
magnitude slower than when initially written, because the development of so many
ancillary features led to an explosion of runtime dependencies that cumulatively
slowed the app down. Their solution will be to accommodate a new database column
by adding an if-else to the corresponding model’s test factory, which will
make every existing test even slower still.
This anecdote describes a compounding effect. For each feature that’s added, the complexity of each existing thing increases, making it even more costly to add something later. Because most organizations are bad at saying “no” to bad ideas, having a surplus of engineering capacity is a dangerous thing. One reason (among many) that small teams tend to outperform large teams is that they have the liberating constraint of too little time to do everything and therefore must ruthlessly focus and prioritize.
Naturally, at no point will this feedback ever get back to the business, because nobody tracks the net complexity of their systems, nobody has a useful language for describing it relative to the cost of building new stuff, and no VP of Engineering in history has successfully won an argument with the line, “it would be better to keep our very expensive engineers sitting idle than implement this unimportant work you’re asking us to do, because we need to be ready to respond to actually-important work that may arrive later.” (There’s a reason I’m not a VP of Engineering, if you’re wondering.)
But wait, there’s more! Hiring too many people and retaining them to the point that they’re tasked with make-work doesn’t just make the technology worse, it has corrosive knock-on effects on human relationships as well.
This is to say nothing of the feedback loop between technology and human organizations. The number one reason companies decide to break up a monolith into services is that the human organization grew so large that it had gotten unwieldy to work in one system. But we’ll save discussion of Conway’s Law for another day.
If you waste people’s money, they may stop trusting you
Once an engineering organization has built whatever software was consuming so much capacity, and once they have started doing lower-priority work to occupy their newfound excess capacity, the business’s executives will eventually notice that they’re paying as much as ever for software but receiving less value than ever for it. And what’s a reasonable defense, when simple changes start taking longer to deliver than major features used to take as total complexity rises?
Years ago, I met a C-level executive of a client in passing in a hallway. We’d never met before, and I wanted to make a good impression. The first thing he said to me: “why does it take 800 people to keep this web site running?”
Gulp.
Technologists sometimes act like we’re the smartest people in the room, but it doesn’t take a MacArthur grant recipient to be dubious when a very expensive-to-build software system just so happens to cost the exact same price to keep running over time. It strains credulity to imagine that software—a product whose one unique trait is the automation of abstract tasks for nearly zero marginal cost—should cost as much to operate as it did to create. It’s no surprise, therefore, that engineering leaders who hired too aggressively often find themselves contending with a dynamic of eroded trust among other executives. (Speaking as someone who’s taken this call, it is decidedly not fun when a CEO opens with, “I’m looking to replace my entire engineering department with someone I can trust.”)
What should managers do now?
If your company is already far enough along the above bell curve to be experiencing layoffs, I’m afraid hearing this now won’t do you much good. But if you’re earlier in the journey, there may be time to adjust strategy and prevent future-you from being on the wrong side of this situation down the road. If you’re a manager or executive and any of this has resonated, I’d be happy to talk to you about how to find success bringing in outside developers on a contract basis. I’ve assisted numerous founders and technology leaders with hiring contractors and agencies for the first time, and I’m always delighted to help.
Below are some common questions I routinely help managers navigate. The answers differ for every company, so there’s no need to worry that I’ll pitch Test Double as the solution to all your problems. (I may make unsubstantiated claims that we’re the most fun to work with, though.)
- Should contractors be integrated into the team or given more compartmentalized, discrete things to work on?
- What rates should I expect to pay?
- How should consultants interface with IT, product, and engineering managers?
- Which situations are best-suited for on-shore, off-shore, and near-shore providers?
- What terms should I look for in an NDA, Professional Services Agreement, and Statement of Work?
- How should I evaluate agencies to determine the best one for me?
Whether you’re new at this or you’ve been burned by contractors before, know that an excellent collaborator is just that, regardless of who signs their paycheck.
(Also, are paychecks actually signed? Is that still a thing?)
What can individual contributors do?
I have to imagine most of you reading this are individual contributors. Perhaps some of whom have recently been on the receiving end of layoffs that ultimately stemmed from poor planning by leadership. Losing one’s job as collateral damage of decisions that were way above your pay grade can make people feel like they’re no longer in control of the trajectory of their career. But there are a few things you can do to both reclaim a sense of agency and to avoid this situation in the future:
- Insist on understanding the basic finances of each prospective employer—stuff like funding, revenue, profitability—before accepting an offer. Some companies won’t share any of this data with you, while others will happily talk you through all of it. Even before Test Double became employee-owned, we openly shared our headline financials monthly with the entire staff on the premise that we can’t ask people to make financially-sound decisions on behalf of the company if we withhold the company’s financials from them
- Work within your team to identify the business value of whatever it is you’ve been chartered to do. How does it make or save your employer money? How much? Can you calculate it? Can you automate that calculation in a dashboard or chatbot? Having everyone on the team thinking about this will influence decision-making in productive (dare I say, valuable) ways. Trust me, executives appreciate few things more than upstream feedback about how you’re making them even more money. If you’re unsuccessful—if these questions are uncomfortable to ask, hard to answer, or trigger conflict with managers—that’s valuable feedback, too
- If the writing feels like it’s on the wall—the major things to be built have already been built, teams complain of having too little to do, and it isn’t clear why the stuff you’re being tasked with is valuable—trust your gut. Raise your concerns now. Consider looking for other opportunities that will provide a more challenging environment to learn in (making you easier to hire) and an employer that will derive more value from your work (making you harder to fire)
This is a challenging time for everyone in the industry. Software is still a nascent profession, but we’re running out of excuses for seemingly never learning from any of our mistakes. It’d be neat if we worked to ensure that this time will be different.
Join the conversation on our N.E.A.T community
Not a N.E.A.T. community member yet? More info.
If you enjoyed this piece and want to keep up with what our double agents are up to, you should check out our monthly newsletter.

Justin Searls
- Status
- Double Agent
- Code Name
- Agent 002
- Location
- Orlando, FL