Elixir like a local
- Publish Date
- Authors
- Eric Newbury
It has taken me multiple read-throughs—and about two more years of production experience—but I think I’m finally starting to understand and apply the material in José Valim’s excellent blog post You may not need Redis with Elixir. Elixir is quite a flexible language, and it is possible to carry over many infrastructural patterns from other platforms like Ruby. However, by leaning on Erlang tooling, which predates many of the external infrastructural services that have become de-facto standards in modern web applications, we have the potential to boost performance and cut costs at the same time.
Cutting costs
How so? In recent years, we’ve been embracing the “single responsibility principle” not only in the design of our code but in the infrastructure we stand up. We run a Ruby application server like Puma to handle web requests, we run a Sidekiq service to handle the execution of background jobs, we have a separate Redis instance for caching and synchronization of distributed and horizontally scaled applications, perhaps Kafka for pubsub, and of course an external database. All of these services cost money.
I would make the argument that “single responsibility” makes the most sense as a logical separation but not necessarily as a physical resource separation. For example, Kubernetes has a logical separation of nodes (pods), but physically, it might run multiple pods on the same VM to make use of all the available CPUs. The Erlang VM is similar, with many logical separations for data stores, caches, pubsub, and more. But all run under the same environment where they can make use of the existing infrastructure. Why pay for an external resource to sit doing nothing during light load when you can use only what you need when you need it?
Increasing performance
Of equal importance, the performance of your application is likely to increase after eliminating the latency of network calls to external services. Even if the node has to reach out to a different BEAM node on the network for some state only available on a leader node, you still save time used for data serialization and deserialization to generic formats like JSON, instead allowing Erlang processes to send native messages to each other.
What makes this possible?
This is one of the sections of José’s post that took me the longest to make sense of. As much as I can simplify it, we commonly see two types of language runtimes: Single Core Concurrency Platforms (Ruby, Python, NodeJS) and Multi Core Concurrency Platforms (Erlang, Java VM)
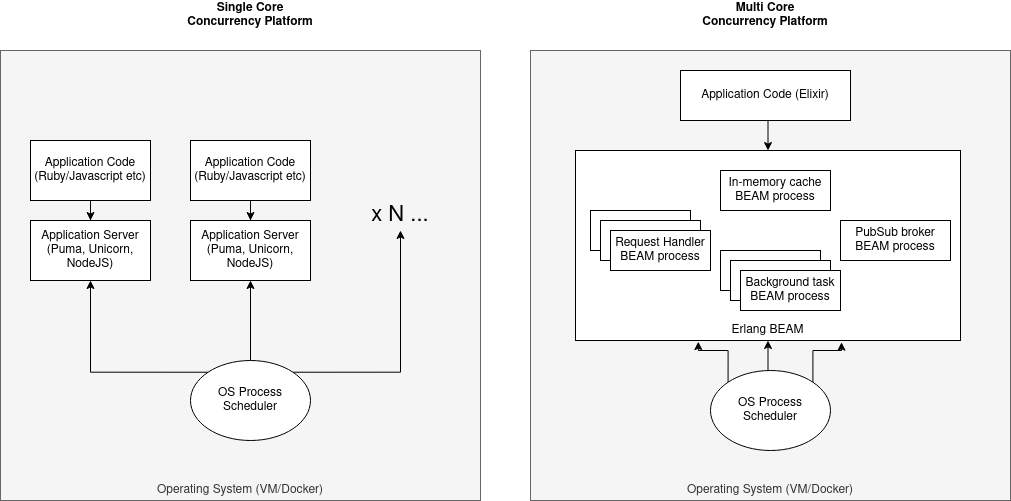
As seen in the left figure, single core platforms run the entire application code from a single host
operating system process. Of course, there might be some support for “Threading” within that
ecosystem to provide some level of concurrency like Ruby’s Thread class. This can be helpful for
allowing other work to continue while waiting for IO but doesn’t allow the use of multiple OS cores and
true parallelism—a requirement for running any kind of embedded services like an in-memory database
or pubsub. As an aside, managing multi-threading in languages that allow mutation and shared
memory between threads can be quite hard. And this is generally discouraged in
favor of external background job processing services like Sidekiq.
On the flip side, multi core concurrency platforms like the Erlang VM embrace an entirely different paradigm. The runtime boots up once on the host OS and reserves a pool of OS processes. It might not use all of them all the time—enabling the OS to prioritize other processes—but they are available to the Erlang VM whenever it needs to execute a parallel workload. From there, your application code can set up long-living BEAM processes (super lightweight abstractions that the BEAM can dynamically assign to its pool of OS processes to do work). With this paradigm, it is now feasible to run background work simultaneously with high throughput HTTP request handling.
Of course, other platforms like the Java VM and even modern Ruby alternative runtimes have similar capabilities, but I would argue that the Erlang ecosystem is more mature, with a more comprehensive set of tools available for solving a lot of the common problems that cause us to reach for external services. And again, because Java is Object Oriented and leans heavily on mutability and shared memory, in practice, building maintainable concurrent code can be a bit of a challenge. Erlang leans on immutability and the Actor Pattern to allow communication between processes, which I have found to be a less painful experience.
Conclusion
The blog post goes on to elaborate on some of the common use cases of Redis in a tech stack and how we can use built-in services to do the same. In practice though, I’ve found one of the biggest barriers to letting go of Redis is the need for some kind of global state store so that your application code can horizontally scale up the number of nodes. In a follow-up post, we’ll explore an additional scenario, managing a distributed in-memory store with an acceptable level of consistency.

Eric Newbury
- Status
- Sleeper Agent
- Code Name
- Agent 0063
- Location
- Caldwell, NJ