Field Report: RubyKaigi
Tape-delayed coverage of Japan's national Ruby Conference
- Publish Date
- Authors
- Justin Searls
That’s a wrap! RubyKaigi 2023 has now concluded! Please enjoy this reverse-chronological summary of many of the highlights of what turned out to be a terrific conference! Follow future coverage by subscribing to our newsletter.
Thanks! 💚
It’s already Day 3 somehow! It’s been awesome to see everyone and witness so many impressive, informative, and inspiring presentations so far. The social events have also been a ton of fun. Last night, I attended the RIZAP’s after-party which was conducted like a traditional nomikai and was an absolute blast. The RIZAP folks, who are investing in building out a Ruby team (from just a handful of engineers to 50 in the past year, and a goal of doubling again by next year’s Kaigi) to work on their ChocoZAP app, were all really gracious hosts who seemed to understand the spirit of Ruby.
I was fortunate enough to be seated across from Matz, so I had to insist on getting a photo. When I asked for a selfie, he initially demurred—not because he didn’t want a picture, but because technically the word “selfie” shouldn’t apply to two people. I asked for an alternate name and he suggesed “withie.” So here’s my annual withie with Matz:

Without further ado, your RubyKaigi Day 3 content:
- First, a how-to on buying coffee at Japanese convenience stores
- Ruby Committers vs. The World
- Hasumi-san’s embedded SQLite implementation
- Nakajima-san’s implementation for RubyGems support in WASM
- This building is shaped like a violin, FYI
- Kokubun-san gave a leJIT overview
- Kuwabara-san showed me how to use RBS
- Soutaro-san’s closing keynote
- RubyKaigi 2024 is in Okinawa!
- Wrap-up interview with Kokubun
I interviewed Kokubun Just-In-Time
After the first after party (but before the second after party), I sat down with Kokubun-san to discuss his talk on RJIT (and a bit about JITs in general) and why he built tools to make it easy to make your own JIT. We also discussed our favorite takeaways from the conference and what we can look forward to next year in Okinawa.
Our conversation was a great way to cap an awesome week—I hope you’ll watch it!
RubyKaigi 2024 is in … Okinawa!
During his closing remarks, Matsuda-san announced the location and date of next year’s RubyKaigi, and it’s … Okinawa!

I hope that this field report has motivated you to consider coming to next year’s conference! It will be held in Naha, Okinawa, May 15-17. And the weather in Okinawa is usually gorgeous in May, as well. See you there! 🏖️
Closing keynote
Soutaro Matsumoto gave the closing keynote and it was a deep dive into his work writing the RBS parser, explaining how top-down parsers work and walking us through some of the noteworthy challenges he faced.
Because I’ve already stretched my understanding just trying to see how RBS is used today, I won’t try to recap Soutaro-san’s exploration of its implementation. Suffice it to say it was a rigorous and detailed discussion of what it’s like to design a parser of type annotations. One obvious-in-hindsight takeaway is that it’s much simpler to parse type signature files in RBS than Ruby itself, so it was actually a bit more approachable than some other explorations of Ruby parsers put forward during the conference.
Towards the end of the talk, he shared this slide counting that there have been 9 RBS and type system talks at this and last year’s RubyKaigi events, and that this really brought him a lot of joy, given how much work he’s invested into RBS and steep:

I also can’t help but chuckle at the symmetry that the first RubyKaigi in Matsumoto was kicked off by a Matsumoto keynote and wrapped up by a Matsumoto keynote.
As this is my final talk recap, I suppose this can also serve as a conference content recap to a certain extent as well. If you’ve read my coverage so far you would be right to conclude that “wow, 2023 is all about parsers and type systems.” Both topics got a ton of attention, to the point that they emerged as overarching themes in the hallway track as well. It was a welcome, if unfamiliar, experience to overhear attendees at another table at lunch discussing the trade-offs of the two competing parsers. Or people lingering after a session leaning over a laptop to compare different editor integrations for type systems in Ruby and how they could each be improved.
It definitely seems that by drawing everyone’s attention to the areas of greatest contemporaneous development activity in the Ruby language, it seems like Kaigi may be accomplishing a corrolary to Linus’s Law: given enough conversation, all edge cases are covered. There’s something really impressive about RubyKaigi’s ability to draw its attendees—as users of Ruby—closer to the areas of active development. As Matz shared in his keynote, fast feedback from the community is key to the advancement of the language.
So that’s how you use RBS

Masataka Kuwabara gave a talk on how to use RBS. There’s also a companion blog post full of resources
Kuwabara-san started the talk by showing a new command that displays the result
of removing the types found in b.rbs from a.rbs:
$ rbs substract a.rbs b.rbsWhy would this command be necessary? If you want to run an RBS generator against a large application, the generated code is not necessarily perfect. For example, if you run RBS against the following Ruby:
class C
def foo(int) = int.to_s
endIt might generate an incomplete type signature like def foo: (untyped int) -> untyped. Of course, it would be wrong to hand-edit the generated file because
you couldn’t regenerate it without losing those edits (a common phrase I use:
“never trust a generated file you can’t regenerate!”). As a result, subtract
is necessary because it allows one to write a second .rbs file by hand that
provides the correct type signature and then effectively merge it with the
generated RBS file. A workflow like this was shown:
$ rbs prototype rb --out-dir=sig/prototype --base-dir=. app lib
$ $EDITOR sig/hand-written/foo.rbs
$ rbs subtract --write sig/prototype sig/rbs_rails sig/hand-written
# Run your type checking
$ steep checkThis is the relevant pull request.
The talk also included a demonstration of using the rbs, rbs_rails, and steep gems in an example Rails app. The demo also showed off Satouro Matsumoto-san’s rbs-syntax and steep VS Code extensions, which both seem to do everything you’d want them to from an LSP diagnostics perspective.
Let’s get our JIT together
Takahashi Kokubun’s talk on hacking a JIT written in pure Ruby was a lot of fun. If you’re not familiar with Kokubun-san, the intensity of his efforts has recently made him the most active contributor of CRuby! He works for Shopify and is helping them integrate YJIT into Ruby.
He started his presentation with a brief history note: MJIT was developed in Ruby 2.6, YJIT was started for Ruby 3.1, and the recently-announced pure-Ruby RJIT targets Ruby 3.3. Because RJIT is written in pure Ruby and has similar performance characteristics to MJIT, it is a great way to inspect what the JIT is doing in a more familiar setting than C (MJIT) or Rust (YJIT), so it seems like a great tool for learning.
Kokubun-san did an admirable job giving a whirlwind explanation of assembly language and how basic JIT compilers work, but I couldn’t hope to replicate it as clearly here.
Our friends Aaron and John Hawthorn then appeared, because both have been experimenting with toy JIT compilers:

Kokubun-san explained that one of the best ways to learn how JITs work is to try making one! He event created a ruby-jit-challenge repo as a workbook to walk you through compiling and enabling your own Ruby JIT that you can use as a starting point.
The bulk of his talk was spent describing general strategies for how a JIT can optimize performance. He described side exits, redefining methods so as to optimize them, constant redefinition, and register allocation for the VM stack (i.e. storing instructions directly in CPU registers instead of in memory in the VM stack). While I regret that it’s been nearly 20 years(!) since I’ve written a line of assembly—and therefore I don’t have much to offer by way of useful commentary here—it’s nevertheless very exciting to see so much investment from Shopify into YJIT. To also see such impressive performance results so far, and so much energy and enthusiasm from its contributors surely bodes well!
This venue is great
Even though Matsumoto is a small city, the conference’s venue has been really lovely. I just had to take a minute to share this fact Matsuda-san pointed it out to me yesterday. Because the Matsumoto Performing Arts Center is primarily a concert hall, when viewed from above, the building and its surrounding park is shaped like a violin:
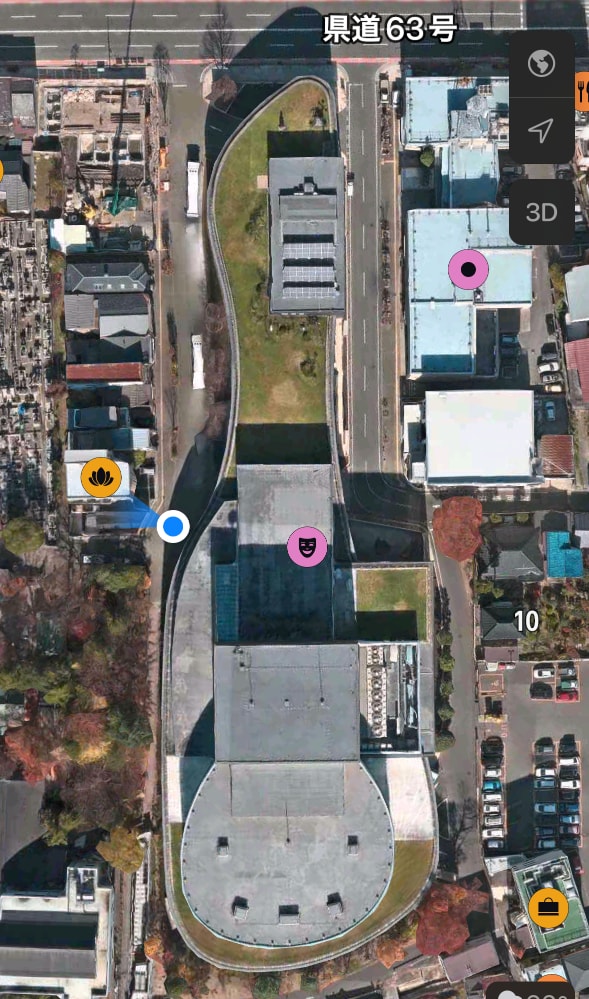
So I guess that explains why I always felt like I was veeering to the left as I walked down every hallway.
Loading Gems in the browser with WASM

Shigeru Nakajima performed a talk that I’d been looking forward to since it showed up on the schedule.
I’d been aware of Ruby 3.2 officially supporting WASM (and therefore, running in the browser), but hadn’t seen any demos yet. Nakajima-san assumed roughly that level of familiarity so he started by showing a Wordle solver clone that he wrote in Ruby with WASM that you can play with online
I gotta say, viewing source and seeing this was pretty exciting:
html <script type="text/ruby" src="wordle_search.rb"></script>
(There are a number of other Ruby on WASM demos showcased on GitHub, you might want to take a look at.)
However, it didn’t take him long to identify a pretty major problem with this WASM implementation: you can’t use gems! The csv is OK (since it’s a default gem), but third-party gems are not supported. Additionally, the file system is read-only.
Before diving into a solution, Nakajima-san reminded us that it hasn’t been very long since JavaScript packages were an unsolved problem, either. He walked through the history of npm, Browserify, bundlers, and so on, until we finally saw the emergence of import maps. These all fall into two categories: those that are bundled before execution (e.g. esbuild) and those that are resolved dynamically at runtime (e.g. import maps).
His take (and I found it relatable) is that waiting on a build step—even if you can speed it up with a watcher process—is anthithetical to the experience of Ruby development, so he set out to find a way to implement import maps for ruby.wasm
His first challenge was figuring out require and require_relative. While
require_relative paths can be logically inferred without an import map,
require naturally requires some equivalent to the Ruby load path in order to
know which file to load. He then showed off his implementation and how it’s
solved for both, by requiring two files, and even recursively loading a file
that was required by one of the files.
The next challenge was figuring out what to do about fetch, which of course
returns a promise and which Ruby lacks. So he wrote a JavaScript function that
handles the fetch and returns it.
The next challenge to this approach is that the default stack for Fiber is 256KB
and this resulted in a mere two calls to require_relative triggering a
SystemStackError. Fortunately, by setting the RUBY_FIBER_MACHINE_STACK_SIZE
environment variable, he was able to increase the stack size to a more
comfortable 20MB.
The next challenge was to figure out what to do when two direct dependencies
depend on the same transitive dependency (i.e. if you require a.rb and b.rb
and they both require c.rb). You don’t want to fetch the same file over the
network multiple times, so he kept those requests in a stack to ensure that he
didn’t thrash the network unnecessarily.
Because you currently need to run to gem install on the server to host the
gems, in the future he described how we should make something like the
UNpkg-like CDN for Ruby gems as importable modules, maybe
called ungem.org.
PicoRuby and SQLite and Keyboards

I wasn’t sure what to make from this talk’s abstract, but Hitoshi Hasumi’s talks are always entertaining, because he often takes his hobbyist zeal for Ruby to ridiculous lengths, no matter how many tools he has to invent along the way.
Hasumi-san is the creator of Pico Ruby which is an implementation of mruby suitable for running on extremely low-power hobbyist devices. He opened the talk by showing a quick demo creating a SQLite database and inserting a few records using the sqlite3 API, which didn’t seem particularly noteworthy at first glance. But then it became clear that—because the SQLite3 doesn’t run on embedded platforms, he had to reimplement much of it himself.
I’d be lying if I said I followed everything that this work entailed, but this diagram should help illustrate that there’s an entire stack of facilities SQLite3 normally depends on to work and which were absent in his environment. Most notably, a virtual file system for the library to hook into:

The bulks of the presentation described the various VFS function points he needed to implement for SQLite to be able to write directly against his SD card.
Listening to Hasumi-san explain how he did all this, I felt like a jerk for wondering it, but I kept asking myself… “but why, though?”
It turns out, he had a reason! All of this work was in service of embedding a device into his custom keyboard. Here’s what it does:
- Insert an SD Card into the embedded microcontroller running Pico Ruby and his custom SQLite bindings
- While he types on his keyboard, record every keystroke, including the location and value of each key
- Plug the SD card back into his computer to analyze his own usage
- Identify which easy-to-reach keys are under-utilized compared to harder-to-reach keys
- Improve his keymapping so that his keyboard’s custom keymap is always custom-tailored to his exact usage.
Woah.
This sort of hobbyist adventurism is just incredible. It’s so fun to see people continue to find creative use cases for Ruby for no reason other than to bring themselves joy, and then for them to share that joy with others. It’s inspiring and has given me a couple ideas of projects I’d like to hack on when I get home!
Ruby Committers vs. The World

The first session of the last day at RubyKaigi is always Ruby Committers vs. The World, in which every committer present sits on stage (in the special blue shirts they receive for being committers!) and fields questions about the language. Topics include everything from the motivation for various features, brief progress reports, advocacy for people’s pet topic certain bugs, and of course opportunities to press Matz to commit to favorable decisions on the spot.
This year, the big question posed directly to Matz was, “if Ruby 3.3 ships with both Kaneko-san’s new universal parser and YARP, which will ship in 3.4?” As you might expect, we didn’t get a straight answer, though he did indicate he was impressed by YARP’s performance, portability, and modern API—which gave me the sense that it will become the default so long as its team continues to invest in its development.
Matz was also asked whether the next version of Ruby after 3.3 will be called Ruby 3.4 or 4.0 and he replied: “I have no concrete plans, so don’t ask me about that.” However, he decided to go on and shared something interesting about the long-term governance of Ruby. Matz described the 4.0 transition as an opportunity to serve as a “test bed” for potential leadership models for Ruby that could continue beyond his retirement. He joked that “unfortunately, I am not immortal,” and explained that none of the current committers seem to want his job enough to succeed him as BDFL. As a result, he described the idea of 4.0 as a social project as much as a technical one, using it as an opportunity to experiment with leadership and governance approaches in parallel with the continued development of the Ruby 3.x series, and then declare Ruby as “4.0” once he feels confident that Ruby is in a good place to survive him and live on to become a 100 year language. This comment struck me as unexpected and refreshingly frank. Transitions like this are incredibly fraught and take careful planning; by creating enough space to try multiple approaches until one can be proven out as successful, the odds of success will be much higher. As a result, Matz’s response made me feel optimistic about Ruby’s long-term prospects.
In previous years, this session was conducted in Japanese (with professional translation available to foreign guests via headsets), but this year they switched the format to English. I felt like this was a little unfortunate, both because the majority of attendees speak Japanese (and no English-to-Japanese translation is available) and because the majority of Japanese Ruby committers did not contribute to the discussion, which led the conversation to be skewed towards the minority of Ruby committers visiting from overseas. I don’t have an obvious solution in mind (maybe we’ll have real-time AI translation next year!), but a format that alternated between Japanese and English or with more aggressive and systematic facilitation might have been more successful.
It didn’t break any other news, but I should add that it’s pretty awesome that a session like this exists at all! Ruby committers are treated with reverence and respect by the conference organizers—they receive special shirts, badges, and a dedicated room in which to work and discuss. When combined with the number of talks that are focused on people’s work in and around the language, the event truly feels like it’s about Ruby in a way that RubyConf in the U.S. doesn’t. It would be great to see future RubyConf and RailsConf events support contributors and highlight their contributions to a similar extent.
First, coffee!
Three days is a lot of days, especially when the third day lands on a weekend. So first, coffee! If you’re ever traveling in Japan and need some fresh-brewed coffee in a pinch, I put together this video to show how you can brew your own cup at nearly any convenience store in the country:
Day two has been jam-packed with talks. Somehow they packed in 8 sessions despite a (much-appreciated) 2 hour lunch!
Day 2 content for you:
- Shibata-san’s talk on Bundler and RubyGems
- Shioi-san’s clever implementation of i++ in CRuby
- Sueyoshi-san’s database-aware RuboCop rules
- Endoh-san’s IDE integration for TypeProf
- My interview with Akira Matsuda
EXCLUSIVE: Meet Kaigi’s lead organizer, Akira Matsuda
Matsuda-san was kind enough to spare a precious half hour from his incredibly busy day running the conference to sit down with me and talk a little bit about the conference, what his thinking is behind its design, why the conference travels between different cities, and his thoughts on debates over whether talks are “too technical” or “not technical enough”.
The Ruby community around the world has a lot to thank Matsuda-san and his teammates for, so I hope you’ll take the time to hear a bit about the conference in his own words!
Type inference you can get excited about

Yusuke Endoh (“Mame”) gave a talk about TypeProf that was really impressive.
I’ll fully admit that apart from hearing about TypeProf a few times since it was introduced into Ruby in 3.0, I never even bothered learning what it did. I think I heard “prof” and thought of “stackprof” and assumed it was a performance profiling library, so I never reached for it.
Turns out, I was wrong!
As Endoh-san kindly pointed out in the beginning of his talk, TypeProf analyzes code to try to figure out type signatures. And, validating my ignorant perspective above, he opened the talk by discussing how the initial implementation didn’t really find a strong use case among Rubyists. But, as so many of us have discovered over the last couple years, recent editor innovations that allow IDE-like experiences, whether in VS Code or other editors that support language servers have dramatically increased our expectations of and imagination for what the editor can do for our productivity while we code.
So, Endoh-san and other contributors to TypeProf took this inspiration to embark on a major rewrite for version 2 of TypeProf that’s optimized for use in editors.
Performance
The biggest bottleneck to using TypeProf as a productivity tool suitable for inclusion in an IDE-like editor extension, it had to be much, much faster. The initial version was not written with speed in mind, as a result had to be run from scratch against a codebase each time the code changed, and would typically take three seconds to complete—much too long to tie to a save hook.
TypeProf V2 is not only 3 times faster than the initial release, it also supports incremental updates. That means that for a typical medium-large codebase, the initial analysis might take 1 second to complete, but each edit that you make to a given file will only require ~30 milliseconds.
He explained how they accomplished this, but I struggled to follow it. It was impressive, though!
That VS Code demo
I’m recapping this in reverse, because Endoh-san started with such a brilliant demo that it felt like the first 30 seconds of the talk was worth 40 minutes in most presentations.
Everything he showed off can be played with yourself in VS Code using the TypeProf extension he’s building
Here are some potato cam photos of what he showed.
He started by showing a generated type inference with an unknown parameter type:
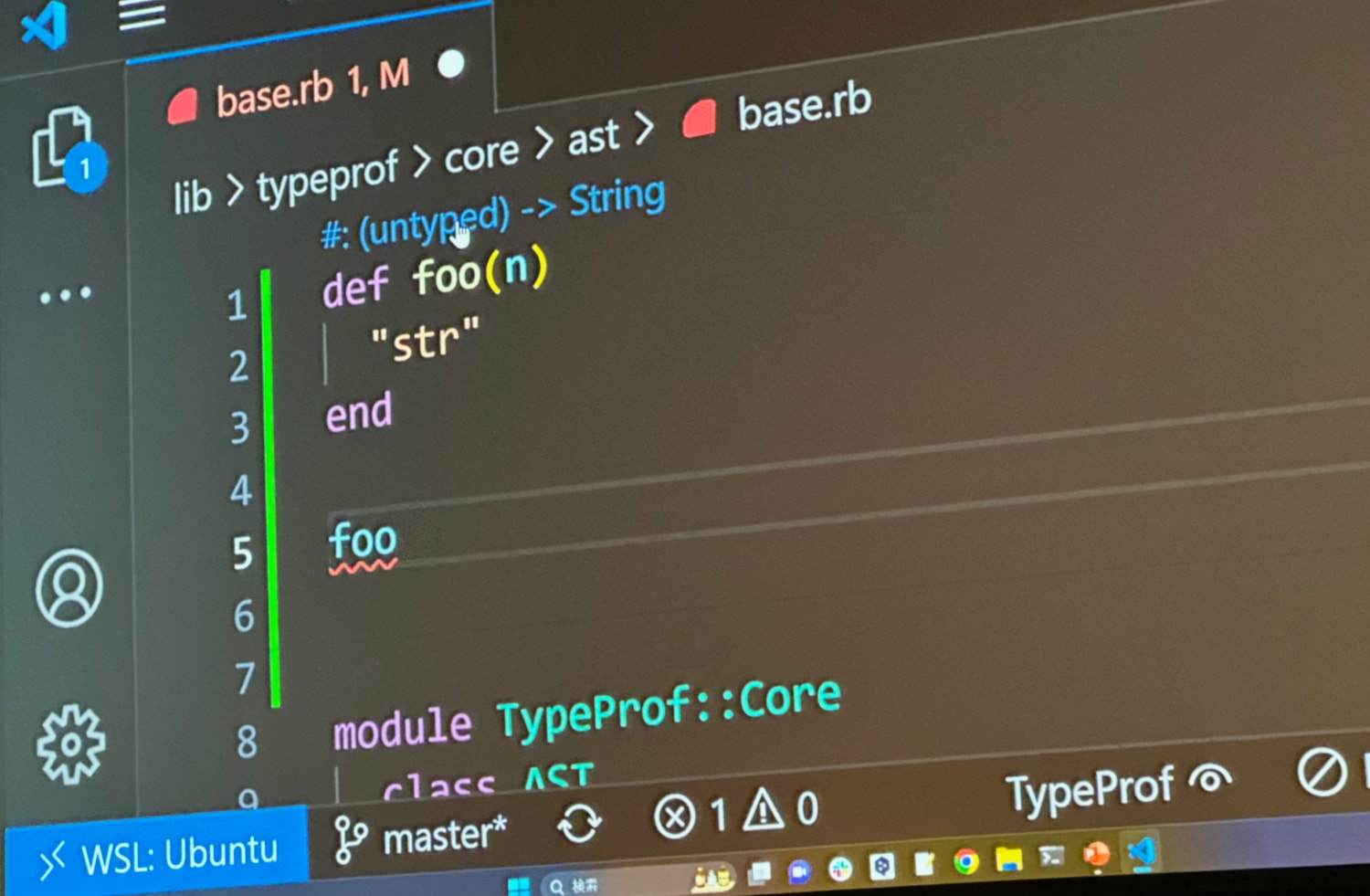
Then, later in the file listing he called the method with an integer, which instantly updated the inferred method signature to show that it takes an integer:
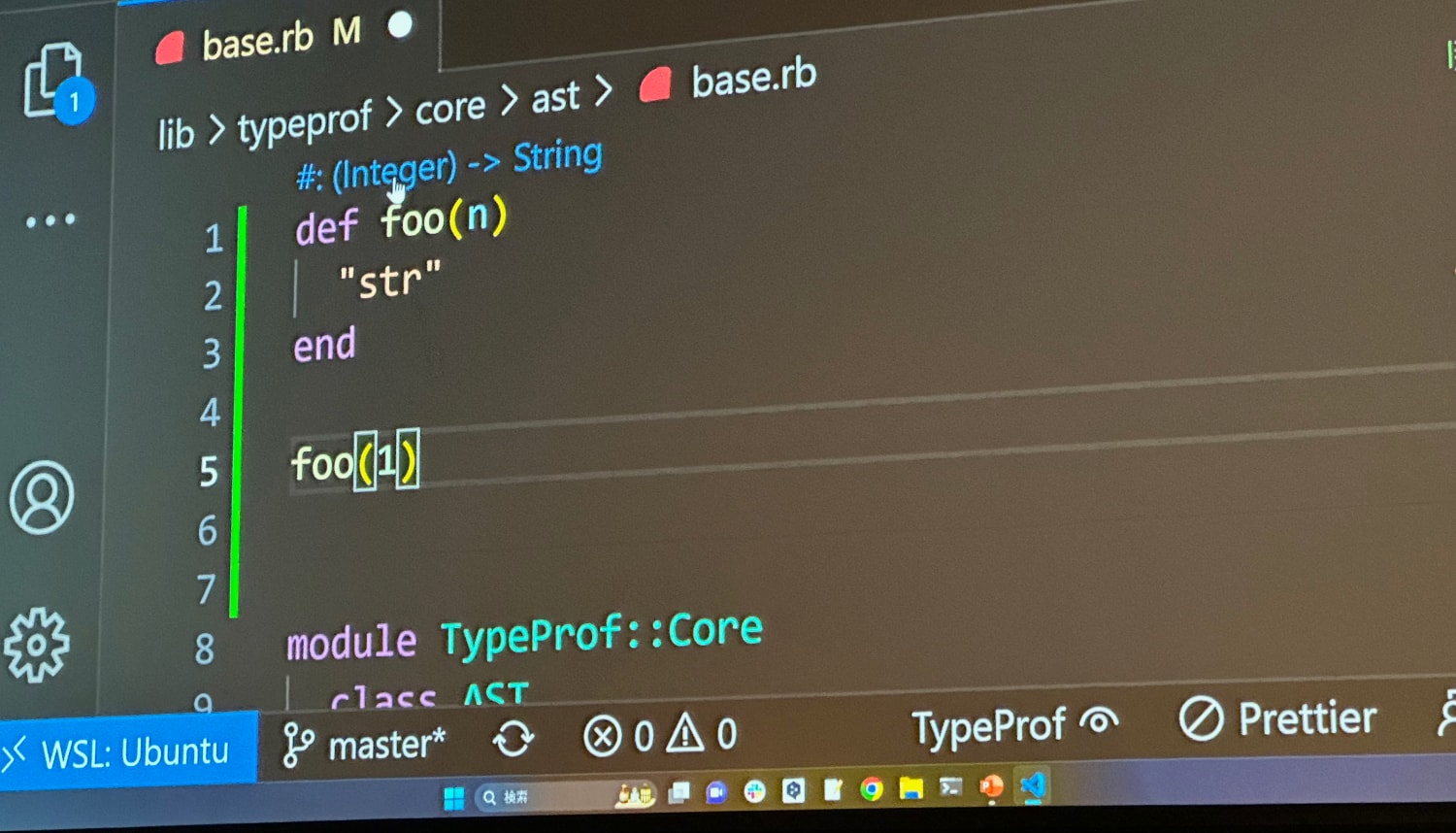
He then called the method a second time, this time with a String. As you can
see, the inference also updated as (Integer | String):
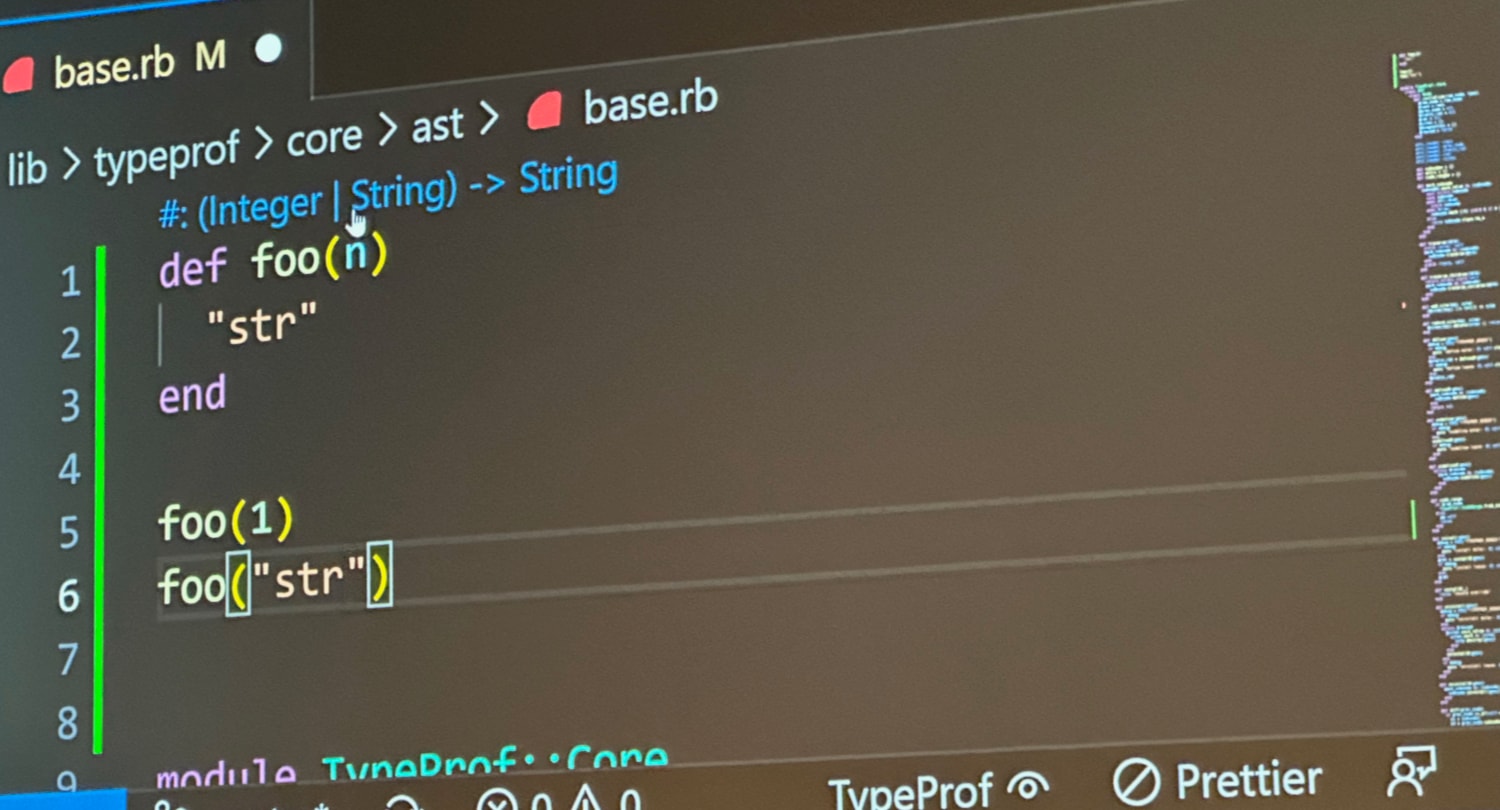
But suppose you decide the method should only accept integers and a type failure should occur when a string is passed? You can click the inference and then edit it as a string and commit it to the file listing as an annotation:
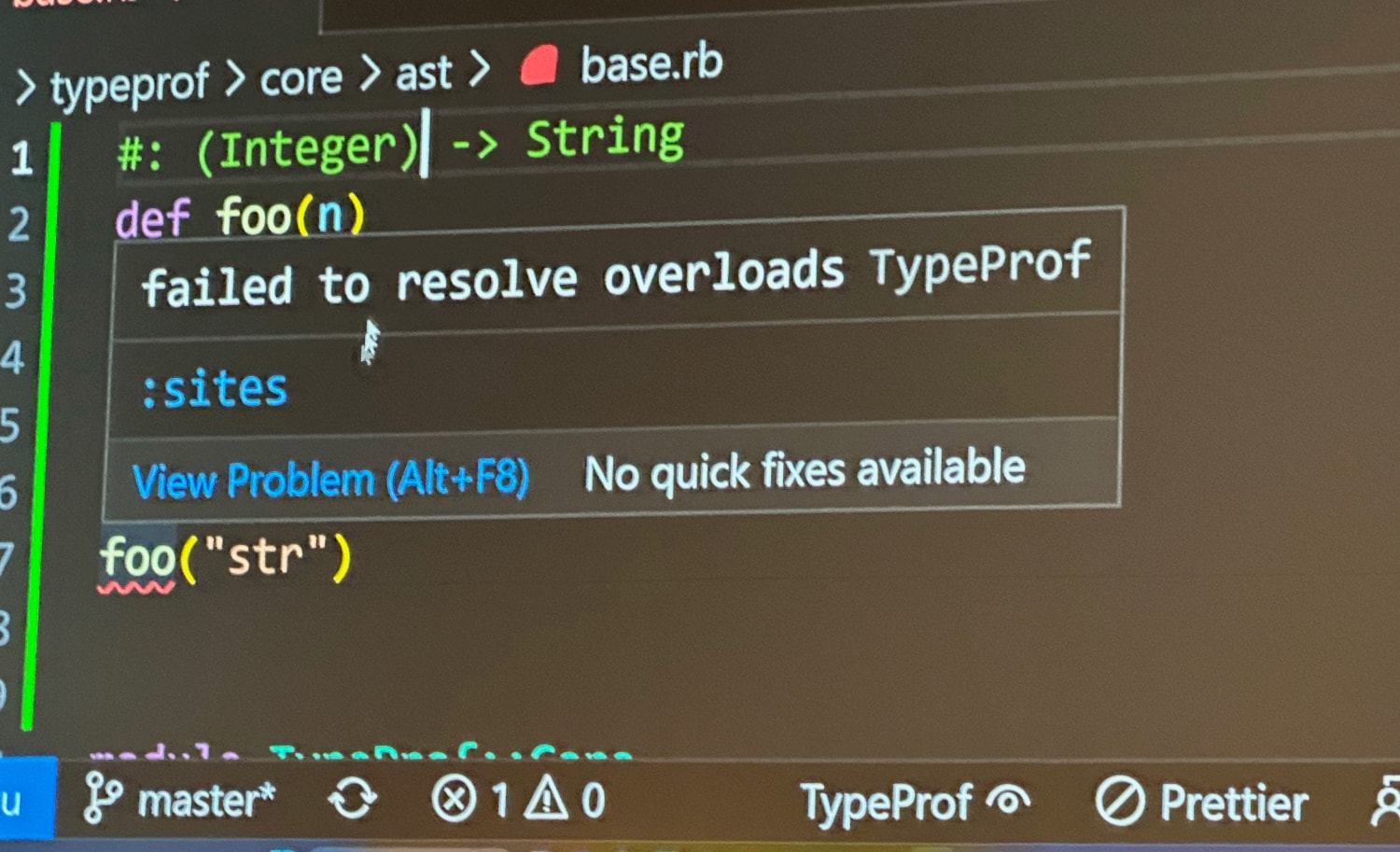
As you can see, the call to the method that passes a String is now underlined as an error.
Seeing this in motion was awesome, because it was all instantaneous! You can also imagine how this type inference driven workflow can give us the benefits of typing in hindsight. Once initially completed, you could walk through the methods you’ve defined and commit the inferred type annotations to enforce the method signature as your code and tests have defined it. For many Rubyists who aren’t accustomed to or interested in planning out all their types up front, this workflow could be an excellent low-friction way to introduce type safety into our code.
I’m really excited to see TypeProf 2 in Ruby 3.3 and to play with Mame’s VS Code extension!
Database-aware RuboCop performance rules

Go Sueyoshi’s talk titled Fix SQL N+1 Queries with RuboCop was a lighthearted exploration of what’s possible when you stretch the limits of what a tool is designed for.
The story of this talk was that Sueyoshi-san entered the Japanese performance optimization competition, ISUCON which is run by the company that makes LINE. The competition has several tracks and it challenges participants to improve the performance of one of several example applications. The Ruby-based stack he targeted included:
- Ruby web server using Sinatra, mysql2, and puma
- nginx
- MySQL
- a runtime environment composed of 3 VMs
Most teams have several developers but because Sueyoshi-san was competing solo, he decided to lean into automation and sticking to tools he already knew well. Because RuboCop automates patterns of undesirable code and because he already had experience writing RuboCop extensions, he decided to attempt something I’ve never heard of before:
- Load the database schema from the database server itself using libgda (via Aaron’s gda gem)
- Identify four common types of SQL strings (heredocs, multi-line strings, etc.) using RuboCop’s AST facilities and then run them through the parser
- Detect common problems for each query, like
whereandjoinclauses on columns that lack an index.
Most of the talk dove into the details of how he used this recipe as a starting point for detecting N+1 queries and even autofixing them. The idea for how he’d even accomplish this took him two months, and another month to actually implement it successfully in both MySQL and SQLite.
As somebody who maintains several gems based on RuboCop, I was really impressed with how much Sueyoshi-san stretched the tool outside its typical usage by wiring up his custom RuboCop rules to inspect the database schema and arrive at judgments about the contents inside of SQL strings.
I strongly recommend you check out the readme for his rubocop-isucon gem to see all the interesting cops he developed for the competition. It’s rather remarkable!
A recurring theme of this conference is that incredible, almost unthinkably impressive things can happen when completely normal people in the community set themselves upon very challenging, under-explored problems, invest time on a single hard problem at once, and pay careful attention as they search for a general solution. Seeing someone pull something off like this is really inspiring!
Implementing i++ in Ruby

The talk on shoehorning an i++
implementation into
the current Ruby parser by Misaki Shioi was an
undeniable crowd-pleaser. Starting with the premise of “who learning Ruby hasn’t
wished for a ++ increment operator?” she went straight to the CRuby source and
figured out how to implement it in
parse.y.
I couldn’t do justice to all the technical details (I struggled to keep up!), but she showed several evolutions of solving the problem that were each expository of how to modify the parser:
- Starting with a simple grammar rule to convert
++to an Integer#succ call - Realizing this will return the incremented value but won’t actually assign
the variable to the incremented value, she implemented a custom method called
Integer#__plusplus__to call instead. This required figuring out how to call it with both the variable name and the binding. - Unfortunately, this caused another issue, in that it will parse
1++as valid syntax and then fail because no variable can be assigned named1, which causes a segfault. This required yet another approach, in which—rather than invent a new grammar rule pointing to a method—she tricked the scanner into interpreting++as+=1, which could in turn be relied on to behave exactly the same way+=1does. (Although expressions likei++ * 2result in some very confusing operator precedence at runtime) - Even after accomplishing this, she realized that the feature would
unfortunately change Ruby’s built-in behavior by breaking existing syntax that’s
(technically) valid, namely instances of successive
+characters followed by an identifier (e.g.+++++++ i), as that would now raise an error. - Knowing Matz couldn’t merge in a feature that would break Ruby, she had no recourse but to resort to forking Ruby into a new language all her own, which she decided to name—wait for it—Ruby++
(And that’s the simple version without any of the implemetnation details!)
You can actually check out Ruby++ on GitHub to see how the actual implementation was made.
This talk was really a delight to watch, because it combined several factors that are hard to pull off but incredibly valuable at a conference:
- Technically rigorous and educational on a topic that’s important (how the language parser works)
- Humorous and engaging, both in presentation and in the fact the entire 40 minute session was a way to work up to a single “Ruby++” joke
- Empathy-inducing, by showing that the trade-offs a language designer needs to make—especially when it comes to weighing preserving compatability against feature enhancements—is incredibly fraught
Fantastic talk. I only wish I was able to understand Japanese a bit better so I wouldn’t have missed quite so many jokes!
Resolving RubyGems and Bundler
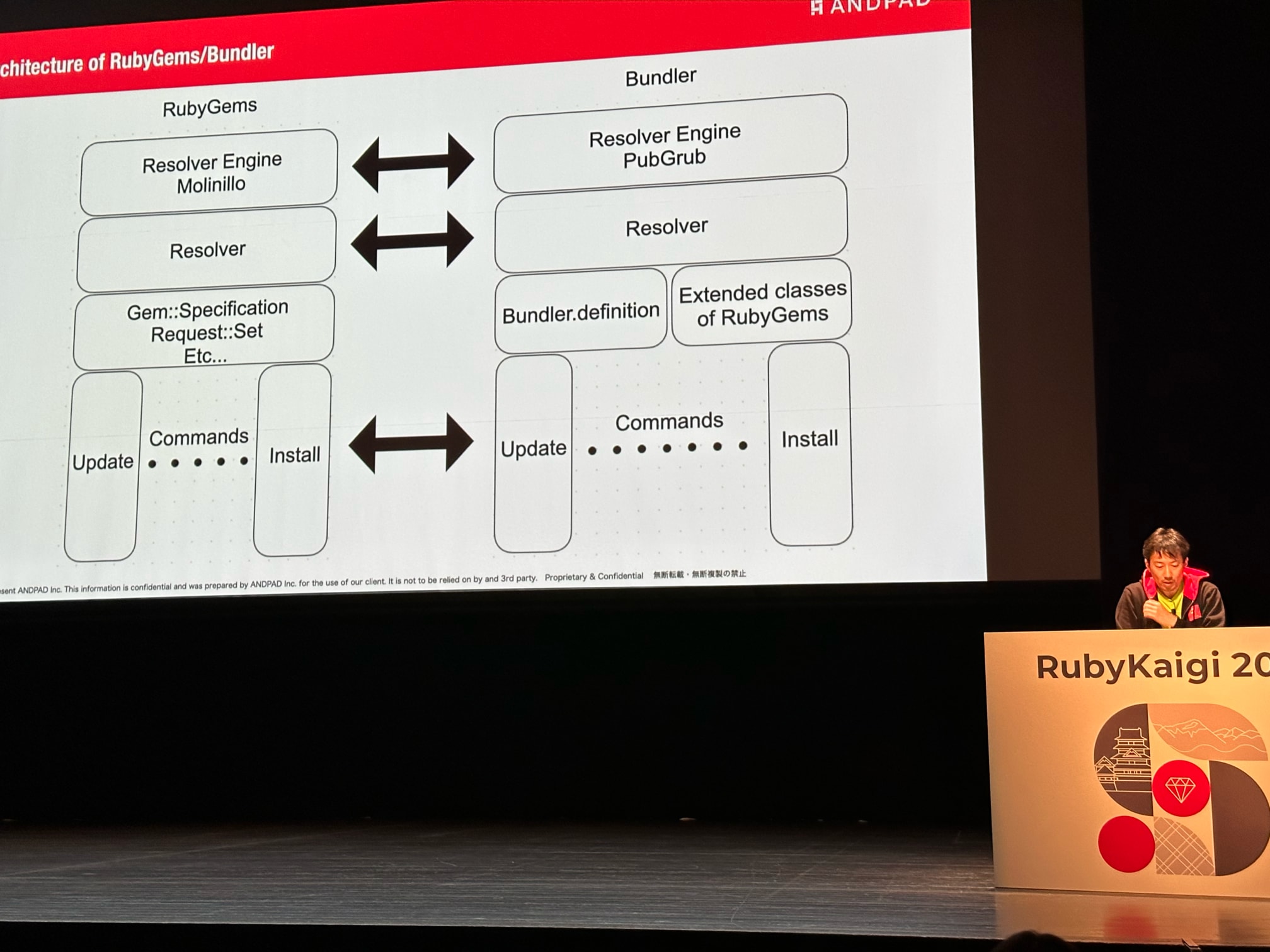
First talk of the day for me was Hiroshi Shibata’s fast-paced tour through some of the edge cases that he—as lead maintainer of RubyGems and Bundler has to deal with.
He spent the bulk of the presentation covering two arcane but tricky problems that have manifested recently. I reserve the right to have completely mistranslated any or all of the following examples:
- RubyGems can’t install the same version of a default gem’s gemspec file if the default gem is already at the latest version, because a flag deep inside RubyGems will see that it’s already installed and skip building native extensions. That’s a pretty sharp edge case, but as the leader of the “gemification” project to extract internal libraries into gems that ship with Ruby, Shibata-san is also the maintainer of many of the gems likely to be affected by this
bundle update --conservativeandgem install --conservativehave different documented behavior (which is fine, if suboptimal), butbundle update --conservativewill (or, past-tense would) often install gems outside the narrow tree of dependencies specified for an update, because whenever PubGrub raised a solver error, Bundler would fall back on retry logic that would lose track of the--conservativeoption
Zooming out, these overviews generated a good amount of empathy for how challenging a job maintaining such an old and convoluted codebase can be. These examples also help justify some of the plans he shared for how to make RubyGems and Bundler faster and more maintainable. In particular, he expressed a vision for:
- Dramatically speeding up RubyGems to close the gap in performance between
running a Ruby script with and without the
--disable-gemsflag. This will require a significant amount of work to reduce the unnecessary scanning of Gemfiles and simplifying the extensions RubyGems makes torequire - Currently, RubyGems and Bundler have almost symmetrical architectures, resulting in a lot of code duplication. They even use separate resolver engines—Mollinio and PubGrub, respectively. In the future, merging the codebases might begin by moving RubyGems’ resolver to also depend on PubGrub as its solver
- The inheritance tree of the
Gemmodule, and subclasses ofGem::Specification, andGem::SpecSpecificationis dizzyingly complex. It’s almost impossible to intuit when you need to callgem.specandgem.spec.spec, which leads to lots of guesswork and hard-to-read code (see the picture below)

Day one is a wrap! Thanks for your patience as I wrote up all my notes. Here are the days recaps for you to peruse below, in chronological order:
- My kick-off interview with Aaron Patterson
- Matz’s keynote
- Intermission: convenience store products of the year
- Kaneko-san’s talk on his new Ruby parser
- Fujinami-san’s talk on regex performance improvements
- Koichi-san’s discussion of Ractor’s struggles and recent improvements
And with that, I’ve gotta run—day 2 is starting! I’m looking forward to catching Shibata-san’s talk on RubyGems internals.
Reconsidering Ractor

Koichi Sasada gave an impressively frank and reflective talk on the struggles facing Ractor. Ractor shipped with Ruby 3 as a way to take advantage of true parallelization, but has struggled to find much adoption yet.
I’ll keep this recap brief, since Koichi kindly uploaded his slides in advance.
Upon reflection, Sasada-san commented that Ractor suffered from:
- A programming pattern (Actors) for which most programmers are unfamiliar and which might feel especially constraining for Rubyists who are accustomed to greater freedoms
- Using Ractors constrains each Ractor actor from sharing mutable state, which means almost every gem under the sun is incompatible. As soon as any code tries to mutate a non-shareable object, an error is raised. Until the ecosystem of gems plays nicely with these memory constraints, using Ractor will be difficult
- Poorly-factored internals and generally poor performance characteristics made it difficult to justify using Ractor over simply forking a process, as has become customary for Ruby server applications
Similar to Matz’s keynote, Koichi described a chicken-and-egg problem with adoption. Until people start using Ractor, gems won’t be updated to support Ractor and until gems support the Ractor use case, people won’t use Ractor. Also similar to Ruby, while Koichi can’t solve this problem on its own, he can at least goose adoption a bit by improving the performance of Ractor and making its benefits more apparent to users.
The upshot is that he’s improved performance a lot. By incorporating the “MaNy” M:N scheduler that he created for Ruby threads and spoke about last year to Ractor’s own thread management and scheduling, he saw 13-100x performance improvements across certain benchmarks.
The biggest remaining performance obstacle for Ractor is that garbage collection in Ruby is global by default, meaning that—because they all share a single object heap—only one Ractor can perform garbage collection at a time. In the future, he wants to improve garbage collection by implementing parallel GC by taking advantge of ObjectSpaces so a single Ractor running GC doesn’t block all other ones. This will be hard, hwoever, because there are a number of shared objects between ractors, so distributed GC would be needed.
Overall, aside from hearing the interesting technical details of Koichi’s journey with Ractor so far, it was refreshing to hear such a talented and experienced programmer share the struggles of his work to find initial success so openly and with a spirit of optimism and perseverence to continuing the work of improving it. I’m genuinely excited for the future of Ractor, because if performance and convenience begin to approach what we see from forking processes, it might open up new and interesting application architectures that will ultimately be more dynamic and scalable than the rather blunt instrument of configuring and managing child processes today.
Preventing ReDoS attacks by improving regex performance
Hiroya Fujinami’s impressive talk on his work to prevent regular expression based DDOS attacks was the third talk I saw on day one of the conference.
Highlights:
- Like many languages, Ruby’s regex parser is susceptible to so-called
ReDoS attacks, in which attackers will
craft requests with really obscure strings (like setting an e-mail address field
to a 1000-character string chock full of
@characters) designed to exploit edge cases in regex parsers—edge cases that often exhibit polynomial and even exponential algorithmic complexity. As a result, these types of attacks can completely overwhelm application servers, even with a relatively small number of requests compared to other DDOS attacks - Ruby’s regex parser is particularly feature-rich—supporting look-around operators, atomic groups, absent operators, conditional branches, subexpression calls, and back-references—this results in a massive number of vectors for this category
- In order to support backtracking, Ruby’s regex parser Onigmoactually compiles each regular expression into bytecode to be processed on a stack-based virtual machine. Instructions are pushed and popped to handle the various branching paths while matching strings against expressions.
- ReDoS exploits take advantage of the regex engine repeatedly invoking this code many times when matching successive strings
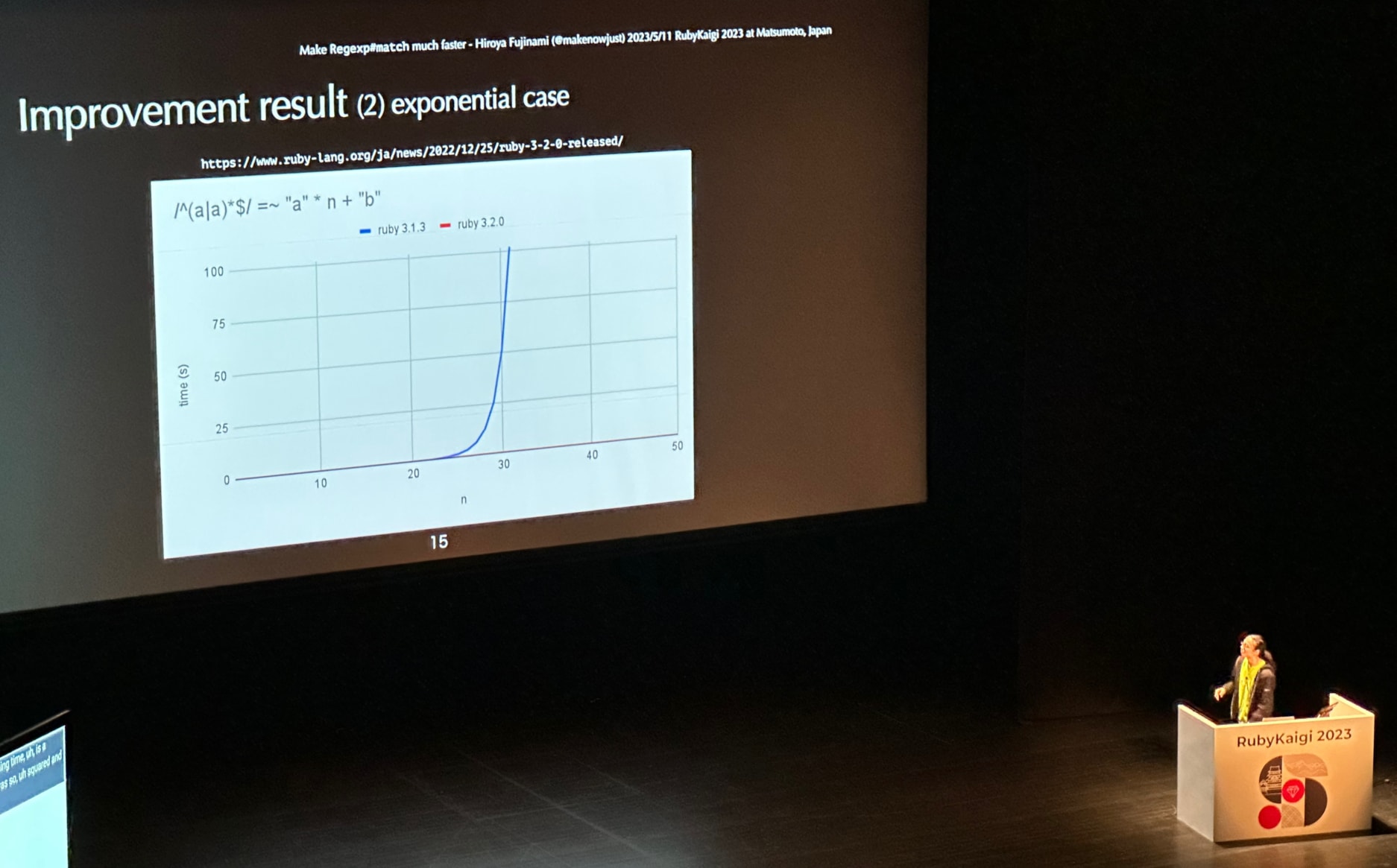
- The solution? Memoization. When thought of as programs, regular expressions are quite small, so it’s not too expensive to store the result of each branch in memory. Doing so allowed Fujinami-san to short-circuit the evaluation of regular expressions that we previously know will not match the expression rather than repeatedly invoking the same bytecode
- The improvements are dramatic. Polynomial and exponential time attack vectors can now be handled in Ruby 3.2 in linear time.
These improvements shipped last year in Ruby 3.2, so your apps can already benefit from this work! Fujinami-san shared a few caveats: namely, if a regex takes advantage of power features like look-around operators, these optimizations cannot be enabled. In the future, he’s considering helping developers with tools like a RuboCop rule or Ruby warning to notify when a regex can’t be optimized. He’s also interested in building an alternate Regex engine for Ruby that doesn’t require a stack-based VM.
Want to dig in further? Fujinami-san’s impressively straightforward pull request is an impressive read!
Curious to see if your regular expressions are benefiting from this optimization? Try calling Regexp.linear_time? and passing in the expression to find out!
The future of the Ruby Parser

The first talk I saw after Matz’s keynote was Yuichiro Kaneko’s talk on his work improving Ruby’s parser.
Some background is helpful to understanding what’s going on, as parsers are apparently super hot right now. Ruby, as an interpreted language, needs to pay the price of parsing our code each time it’s loaded, which means that parser performance is a direct bottleneck on the load-time of our scripts and apps. As other areas of Ruby’s performance have been improved in recent years, attention has now shifted to the parser as a great opportunity for improving both performance and enabling portability across Ruby implementations.
Kaneko-san has undertaken a significant revitalization of Ruby’s parse.y grammar which is passed to Bison to generate the Ruby parser. Simultaneously, Kevin Newton and Shopify are embarking on building a brand new Ruby parser called YARP. The quickest way to think about the difference between these two is that Kaneko’s efforts are iterative, continuing to to generate an LR Parser, while improving the code’s factoring to reduce coupling and make it possible for other Ruby implementations to use the same parser as CRuby. YARP, meanwhile, is a clean-room implementation of a hand-coded Recursive descent parser, which affords it even greater portability and performance but with a little added risk that language ambiguities won’t be caught by a generator.
If you don’t think about parsers very much and the above paragraph was a lot to take in all at once, you’re not alone! I found myself having to remind myself even basic facts about how parsers work, and Kaneko-san’s presentation was a good primer into the work he’s done.
The general arc of his talk:
- He’s done a lot of work to extract Ruby’s parser, which has required a significant amount of decoupling between the parser and lexer, and this effort is almost complete
- This newly-extracted parser can—at least in theory—be adopted by other Rubies like JRuby and TruffleRuby, but it’s important to note that the API interface is massive: there are currently 209 function points that an interpreter would need to bind to in order to adopt the new parser
- As mentioned above, the broad-strokes difference between the two types of parsers
discussed:
- LR (Left-to-right) parsers: Probably better to just read the wiki page than allow me to explain poorly. Relevant to this discussion is that generators like Bison provide certain guarantees (namely, they detect and error if the grammar is ambiguous)
- Recursive descent parsers: crafted by hand and with specific knowledge about the language being parsed, these parsers have the benefit of being designed with relatively few constraints and can take advantage of rules in the language to design bespoke performance optimizations that wouldn’t be possible when describing something resembling a context-free language. By the same token, however, this freedom also requires the implementor to test that the parser works correctly
- The “do dillemma”. The current version of the parser actually specifies four
different kinds of
do. For parsing purposes, thedoyou use in blocks, lambdas, and conditionals, are all totally different things. Figuring out how to detangle this was very challenging, but Kaneko-san’s breakthrough was to borrow lessons from operator-precedence parsing since each of these types ofdo…endexpressions have a well-defined precedence
If I understand correctly, it was just decided this week at the in-person meeting of Ruby Core that these parser improvements will ship in Ruby 3.3 as the default parser implementation. Interestingly, Shopify’s YARP contribution will also ship with 3.3 behind an optional flag, allowing them to benchmark, test, and harden the implementation with the hope of becoming the default in the future.
This season’s convenience store findings
I needed to sleep between talk recaps, so by way of an apology for my tardiness, here are some convenience store items I’ve found so far on my trip:
Click through to my blog for descriptions of what you’re looking at.
Day one of Ruby Kaigi 2023 is in the books! I learned much about live-blogging today:
- Don’t.
It’s just too hard trying to listen in a second language, translate, take notes, and snap pictures simultaneously. So instead, I did my best to stay present, recorded audio in the hope I’d be able to transcribe it later, and make sure to get you—my valued audience—a summary of what went down.
Without further ado, please enjoy today’s recap!
EXCLUSIVE Interview with Aaron Patterson
Aaron and I walked to the conference together and sat down for an interview before checking in. It’s a solid preview for the day that was to come:
We cover a lot of ground in this interview, but in particular we previewed the topics that Yuichiro Kaneko, Koichi Sasada, and Mari Imaizumi spoke on. As a result, the conversation is a good primer for the next generation of Ruby parsers, the future of Ractor parallelization, and why text encodings like UTF-8 are so incredibly important in Japan and other countries whose languages' characters won’t fit within a single byte like the English alphabet can.
Matz’s Keynote

Every year, Ruby’s creator Matz gives the keynote address at RubyKaigi. I’ve seen Matz speak numerous times over the years and while I’ve had the opportunity to witness the most recent several chapters of Ruby’s history, I’ve also enjoyed witnessing Matz settle into and gain comfort in the various roles required of him as Ruby’s creator. As the language’s BDFL, he’s the ultimate judge and arbiter of what is accepted into the language. In public, he’s a marketer and promoter for Ruby, co-founding the Ruby Association and hosting the business-forward RubyWorld conference in his home prefecture of Shimane. But in recent years, it’s been really fun to watch him gain comfort in his role as leader and visionary, charting a course for the language—often with audacious goals (Ruby 3x3) and controversial constraints (no requirement to use type annotations)—and leaving the execution to others.
This talk was, I suppose, a reflection on all of that. He described no new language features. He didn’t tease anything about Ruby 4. He didn’t throw (much) shade on other languages or critics of his approach. Instead, Matz summarized the 30 year history of Ruby—something many of us have heard him share several times—through a novel lens: what were the key lessons to undertaking a project as significant as a programming language that he took from each of the generations of Ruby’s lifecycle that others might be able to learn from.

This may have been the best all-around presentation I’ve ever seen Matz deliver. I found myself nodding along to each of his points, for sure, but also could appreciate the universality of each of the lessons he had taken away from his career overseeing Ruby’s development.
The headlines of each lesson Matz has taken:
- It’s important to choose a good name. Matz marks Ruby’s birthday based on the day he settled on the name Ruby. The other candidates were “Coral” and “Tish”. He joked that it’d be weird to be attending a conference that sounded like “Tissue Conf”, like it was for the paper product industry or something. But seriously, a great name galvanizes our concept of the thing that we’re building and gathering around, and Ruby is undoubtedly a fantastic name.
- Pick your principles and stick to them. Matz marked the first full year of development in Ruby (the oldest version he still has on hand is 0.49) as particularly lonely, but notable in that the general principles of Ruby came into being during that time and they never changed.
- Solicit different perspectives. He initially shared Ruby on Netnews and found it really important to appreciate people who wanted different things from Ruby than he did, or noticed problems he didn’t see.
- Community supercharges feedback. 28 years ago, he started the Ruby mailing list and shared Ruby’s first truly public release (v0.95). (It turns out that the first release wouldn’t compile, even on Matz’s own computer, so it wasn’t until the third email that a working release was available.) What Matz found was that as the community grew, people’s complaints turned out to be incredibly valuable, and by not shying away from criticism and negative feedback was a necessary ingredient to the rapid advancement of the language, because it sped up the feedback loop for improvement dramatically compared to only following one’s own whims and observations
- Users adopt langagues only if they benefit from them. In 1998, Matz released Ruby 1.0. There was no headline feature, it just felt stable enough that it was a good time to call it “1.0” and start promoting that other people adopted it. His takeaway was that there’s a fundamental chicken-and-egg problem to new languages: 99% of users only adopt a language for some defined benefit (as opposed to playing with languages for languages’ sake), but those benefits (like an ecosystem of useful libraries) depend on adoption to materialize. So in the early days of promoting Ruby publicly, he sought out a large enough nucleus of users who wanted to use Ruby for the joy of using it that they would go on and create enough useful things so as to encourage others to adopt it
- Marketing matters. Matz described traveling to promote Ruby. He went to JAOO 2001, which unfortunately coincided with 9/11, which he witnessed via TV in his hotel. Later that year, despite the anthrax scare, he attended the first RubyConf in Tampa in 2001 with folks like DHH and Dave Thomas and scarcely 30 other people. (Pretty remarkable seeing as RubyKaigi drew over 1200 developers this year!) Without the incredible success of Dave and Andy’s Pickaxe book or without David’s famous “build a webapp in under 15 minutes” backpack demo, Ruby wouldn’t be where it is today.
- The importance of maintaining compatibility. While Ruby 1.9 introduced YARV and dramatically improved Ruby’s performance, the release’s lack of compatibility with Ruby 1.8 created a mini-schism that lasted for years. This experience caused Matz to take compatibility incredibly seriously (given the above, if you fracture the community, you will lose the valuable feedback loop you need to advance the language). As he’s commented before, seeing the Python 2.x / 3.x schism occur roughly simultaneously really validated this takeaway for him
- Audacious goals inspire innovation. In 2015, Matz stated the audacious goal of making Ruby 3 three times faster than Ruby 2.0, which he now admits he didn’t totally believe would be possible. But then as he listed off the improvements we’ve seen to Ruby since then, he made a convincing argument that without the audacity of this goal, we probably wouldn’t have seen all the innovations and creativity we’ve seen over the last 8 years, which have really revitalized the language
- Perseverance pays off. After years of withstanding criticism about his refusal to transform Ruby into a language replete with type annotations (as TypeScript is to JavaScript), including comments that this was tantamount to being a “flat earth believer”, he pushed forward and stuck to his principles and vision for what Ruby should be. And now, with the recent innovations in AI, he commented that we can already imagine a world where the computer could reasonably annotate all our types for us based on very intelligent, human-like inferences of the source code, which validated his commitment to not littering type annotations throughout everyone’s Ruby source listings.
My real-time notes follow, completely unedited:
- It’s been over 30 years since starting work on Ruby, so we’ll cover some of the things we’ve learned over the generations.
- The day Ruby was named “Ruby” is marked as its birthday. The other candidates were “Coral” and “Tish”. It’d be weird if we were all gathering for “TishKaigi”, since it sounds like a paper company. But in order to make a good thing, it’s important to choose a good name
- 1993-1994 was a lonely time because I was the only person working on Ruby. The oldest version that remains is 0.49. But even then, the fundamentals of Ruby were already chosen and haven’t changed since. The basic principles and language were settled at this point
- In 1995, I released an alpha of sorts to Net News (Usenet?), but and about 20 people expressed interest and I shared it with them. I learned that it was important to get the perspectives of other people who differing perspectives about things like brace and end syntax, because otherwise I wouldn’t
- I created a mailing list and the first email was 28 years ago. There was no Twitter back then, I released the first public release as 0.95. Unfortunately, I couldn’t get this first version to compile on my machine and I wasn’t able to patch it until I’d sent the third email. What I learned was that “community = communication”. By building a community, people could complain directly to the creator and I could more rapidly get feedback about how to make Ruby btter overall, which was important to its success
- 1997-1998 we released Ruby 1.0. There’s nothing special about the release, but things felt roughly stable so it seemed like a good time. Some people use languages for languages’ sake, but most people (99%) are looking for some kind of benefit from the language. They need libraries, or killer apps, or some other benefit to adopt it. This creates a chicken and egg problem for a language—users don’t join because there aren’t clear benefits and those benefits aren’t created because there aren’t enough users. So we knew we needed more people—we had to seek out more people who used Ruby because they loved it. People who shared in the motivation of appreciating the freedom of using Ruby
- 1999-2004 - The first book on Ruby was published in November 1999. It was originally planned in 1997, but it turns out it’s really hard to make a book. The first English-language Ruby book was published in October 2000. I have a memory about someone towards the end of 1999 who was always expressing interest in writing a book in English? And I said yes please. So I was a little shocked by how he had already finished a draft of the book in 8 months when it’d taken me over two years. So thanks to both of these books, people both here and overseas started using Ruby, and without these books there
- 9/2001 - JAOO conference was a Java conference with people like Martin Fowler and other important people in the industry and I was excited to meet people. So while I was there and watched 9/11 occur from my hotel and I came straight back to Japan.
- It was around this time that I first spoke with DHH was a student and David Thomas went to Florida in Tampa, despite the risk of anthrax. Probably around 37 people came for the first RubyConf. And gradually we grew and saw other conferences around America and the world.
- Dave Thomas and Andy Hunt from Pragmatic Programmer and they wrote a book about Ruby in English (the Pickaxe Book) and that’s why we’re here now
- 2004-2009 is when Rails exploded and web application development became the killer app and explosive growth. We also established the Ruby Association to promote the language for use in business at this time. The lesson here is that using something from a place of joy can create downstream benefits that are truly meaningful. As a programmer, I’m not particularly good at marketing. DHH, though, is an incredibly good marketer. Even though there were some flame wars, it really led to a huge increase in use by business too because it was such a massive productivity improvement over Java and PHP. The real breakout was his 15 minute “backpack demo” video that you can create a todo app so quickly. This was before YouTube! His ability to present it well and market it made a huge difference. Even though marketing doesn’t come naturally to me, I really came to appreciate it. Of course the enterprise is a lot different, where in Shimane at RubyWorld a third of attendees were wearing suits
- 2009-2013 we released Ruby 1.9.1. So there was a new virtual machine YARV which was a massive improvement, however compatibility was a major split for 5+ years between 1.8 users and 1.9 users, because there was subtle differences between the versions. Of course the lesson that backward-compatibility between versions is very important, as we later saw in Python with the permanent schism between Python 2.x and 3.x. I learned that if we break compatibility, we fracture the community, which sets us all back. Fortunately, performance improvements heals all wounds; because 1.9 was so much faster than 1.8, people gradually migrated for the purpose of benefiting from the better performance
- 2013-2015 - Ruby 2 was released over 10 yeas ago(!). Over the years there were many feature requests. The big one was pattern matching, which had to wait until Ruby 3. When discussing Ruby 2 there were so many discussions of how we’d like to include this and that feature. Around the time, the overwhelming popularity of Rails made it feel like the overlap between Rails users and Ruby users was 100%. We had to be careful to not be too swayed by that and understand that popularity comes and goes, but
- 2015-2020 - Ruby 3x3 this catchphrase was actually inspired by JFK’s “not because they are easy, but because they hard. Because that goal will serve to organize and measure the best of our energies and skills”. So by setting a goal of tripling the performance of Ruby 3.0, was a rallying cry to encourage creativity and motivation. Of course when I announced this in November 2015 at RubyConf, I truly wasn’t sure believe this was possible. I released MJIT but it turned out to not significantly improve the performance of Rails applications, but the goal spurred Shopify’s team like Maxime and Kokubun to build YJIT which is truly seeing closer to the 3x improvements. My lesson from this period is the important of leadership and vision to set audacious goals and set ambitious direction, even if other people are to do the hard work
- 2020 “Rails is Dead” – the lesson here is you gotta persevere through challenges and headwinds. DHH “TypeScript sucked out much of the joy I had writing JavaScript, I’m so glad that Matz didn’t succumb to the pressure of adding types to Ruby”. Not preferring type systems when we work in a language makes us like a “flat earth believer”, which is pretty tough. The best way to predict the future is to invent it.
Other notable events:
- Alternate implementations. For other languages, there weren’t really any other implementations like for Perl. But we have many, maybe because they’re easy to make in Ruby’s case. In particular, he highlighted JRuby (2001), IronRuby (2007), TruffleRuby (2013), mruby (2012). It was really awesome and made him really happy to see
- ISO StandardISO/IEC 30170:2012 - to define Ruby as an official ISO standard was an incredibly difficult effort. Endless meetings. But it’s not clear if anything good came from it.
- “100 year language” essay by Paul Graham. I can’t think that far ahead but because Ruby is 30 years old, I feel I can at least see ahead 30 years. So maybe it’s a 60 year language. He called out Concise, Readable, Extensible and Ruby is all these things. Performance, Concurrency, Tools, Types. We have all these things too as of Ruby 3.0’s release with improvements like RBS and Ractor.
- Other things I appreciate. It’s very fun to share Ruby methods and ask it to explain. It got me thinking about types. Why should we write types if the AI can just figure it out for us, so maybe it’s not so bad to be a “flat earth believer”
- Our goal has always been to Create a better World. Both us on Ruby, and Gem authors, and Rails developers. These applications built with these tools benefit and the world who uses those applications benefits. So together we are all working to make the world a better place
I also took a really bad recording of the talk and then ran it through an AI transcription and translation service in case you want to search for something.
After a few days on the road, I’ve finally arrived in Matsumoto. Unlike most conference attendees, I approached from the north, so I got a somewhat different view of the mountains on the way down. Here are a few clips of what today’s trip looked like:
I decided to take the long way to Matsumoto by passing it to the southwest in order to visit my study abroad homestay parents in Hikone before the conference. Then I looped back around to the north in order to spend a day in Kanazawa. I’ve been meaning to go for years based on countless recommendations that they have the freshest, tastiest fish in Japan and several meals later—I’m a believer!
Here are some pictures I took throughout the day:
Kanazawa is known for a sashimi rice bowl called “kaisendon” (海鮮丼) that I’d actually never tried before, so I went on a half-day mission to find the best one I could. I learned shops sell out early, so if you ever attempt this, go as early in the day as you can work up an appetite—they are not small!
Here’s a little video of my fish hunt:
I got into Tokyo during the waning days of the Golden Week holiday, and Tokyo was even more packed full of humans and overwhelming than usual. Adding to that, because nearly everyone takes the same week off, most of the restaurants I tried to visit were closed. Oh well!
Nevertheless, it was great to decompress a little bit and adjust to the time zone change before starting my travels in earnest.
This trip marks my tenth visit to Japan (ranging between 2 to 52 weeks). To mark the occassion, I picked out one of my favorite photos from each prior visit:
You've finished reading…
…but this need not be the end! We’d love it if you also subscribed to the Test Double Dispatch.
Each month, you’ll receive one e-mail breaking down what the Double Agents are up to. Blog posts, videos, open source releases, upcoming events—you get the idea!